
Why is statistical manipulation required in machine learning?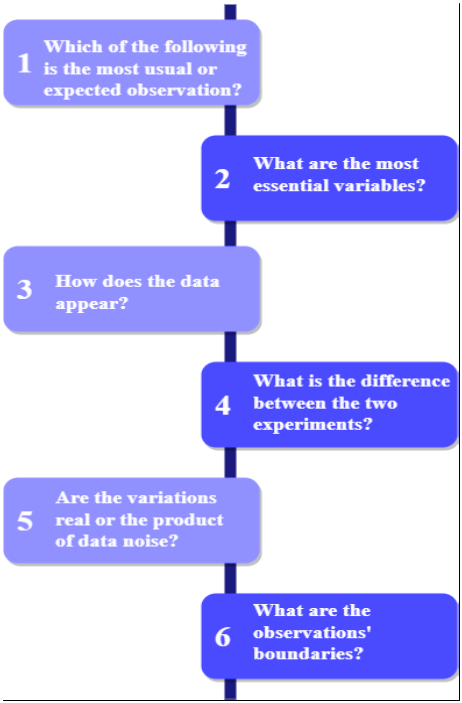
Machine learning requires statistical manipulation additionally recognized as “data transformation” or “data preprocessing” to guarantee that the data employed for training and evaluating models is of high quality, appropriately prepared, and matched with the hypotheses and needs of the selected method. It is a critical stage in the data preparation chain that has a substantial influence on machine learning model performance and dependability.
Statistics
Statistics is a collection of techniques that may be utilized to address key questions about data. On raw materials, Statistics can include a wide range of topics connected to the production, use, and trade of vital resources in a variety of sectors.
Types
- Descriptive statistical approaches may be used to convert raw observations into information that is easy to comprehend and distribute. This includes arranging and summarizing data using graphs and figures. For example, histograms, pie charts, graphs, and so forth. We can run it on population-based sample data.
- Inferential statistical approaches can be used to extrapolate from small samples of data to entire domains. Although raw observations represent data, they are neither information nor knowledge. Some data raises questions are represented in the diagram. This makes use of facts to draw conclusions. To get different conclusions, several tests are run on the sample data, including data visualization, modification, etc.
An analysis between machine learning and statistics
The concept that machine learning and statistics are similar is inaccurate, since there is a fundamental difference between them, which will be explained in the next section.
| Aspects | Machine Learning | Statistics |
| Target | Making Predictions and Decisions | Inference and description |
| Data | Large and complicated, and frequently unstructured | Small and well-controlled Datasets |
| Systematic Model | Adaptable, complex, and data-driven systematic model | Usually, Parametric Model inherited with Assumptions. |
| Interpretability | Model Prediction Reliability is emphasized | Model Interpretability and Presumptions are underlined |
| Successful Evaluation | Accuracy, Precision, Recall, F1-Score | P-Values, Confidence Intervals, Effect Sizes |
| Concentration | Predicting reliability and Generalization | Recognizing Data Distribution |
| Application Domain | Computer Science, Engineering, NLP | Social Science, Medical Research |
| Methodological Strategy | Numerous Kinds of Techniques | Emphasis on hypothesis evaluation and causation |
| Models Authentication | Cross-Validation, Train-Test Splits | Cross-Validation, Bootstrapping |
The table highlights the fundamental distinctions between machine learning and statistics, stressing their various foci, aims, and uses, with machine learning embracing statistical concepts for interpretability and resilience.
Relationship between statistics and machine learning
When we categorize machine learning and statistics as separate domains, we are talking about two alternative approaches to the same challenge. They’re like two bicycle wheels that can’t function without one another. Practitioners in both professions must keep an eye on each other in order to make genuine and useful responses to the challenges.
Both domains predict or estimate output using observation vectors. Maximizing model parameter likelihood in statistics is identical to reducing entropy in machine learning. Although hypotheses and prediction rules are similar, both require scrutiny. Both areas convert data into quantitative assertions in order to achieve accurate results.
While statistics and machine learning have unique purposes and histories, they are interrelated sciences that frequently borrow ideas and techniques from one another. This interaction has resulted in a rich and expanding discipline that uses both professions’ capabilities to handle complicated data analysis challenges, construct strong models, and make decisions based on data-driven information.
Conclusion
Statistical manipulation is essential in machine learning to guarantee high-quality data for training and assessing models, which impacts their reliability and efficacy. Statistics and machine learning have a symbiotic connection, working together to enhance the accuracy of predictions and judgements. Practitioners get valuable insights from both techniques, resulting in a dynamic discipline that leverages the strengths of both for well-informed decision-making.